Beyond the Black Box

“Beyond the…”と聞くと逆襲のシャアを連想してしまう、νガンダム世代です。
それはどうでもいいのですが、お正月に読んだ金融業界向けのLLM論文が面白かったので簡単にご紹介を。
前回の「2回書け」のレポートと違い、次にご紹介する論文は、周囲でも、お話しできたのは大手金融機関のごく一部のデータサイエンティストの方だけで(まあそんなに色々な方々とお会いしているわけではないですが。。。)、まだまだ知る人ぞ知る、存在のようです。
Beyond the Black Box: Interpretability of LLMs in Finance
私が副題をつけるなら、【AIアウトプットは「説明」から「診断+制御」へ】でしょうか。
本論文は従来のXAIが超えられなかった「メビウスの宇宙」を越えてゆこうとする、なかなか意欲的な論文です。
筆者の課題設定を超訳すると
・従来のXAI(特徴量の寄与度、決定木や知識蒸留などのモデル簡素化、可視化、感応度分析・・・)等では、金融で求められる透明性やコンプラ、説明責任に対する要求に不十分
・与信・不正検知・リスク管理・アルゴ取引などの分野で特に求められている。
・欲しいのは「判断の根拠=なぜ?」、「嘘や偏見が含まれていないか?」、「どこを直すとアウトプットが変わるか?」といった内部の動きの見えるか&介入手段。
筆者が提唱しているのは
①観測的アプローチ:
- 層ごとに活性化している箇所を覗く
- 内部の色々混ざった反応色々をが要因分解して視る
- ハルシネーションやバイアスあるときに内部でどんな特徴の点灯があるかを観測
②介入的アプローチ:
- 入力に変化で結論が変わった時に内部のどの部分を差し替え
- ①でみつけた特徴部分を調整することで問題になりそうな出力を誘導
などなどでした。
読んでの感想は
「SHAPやLIMEだって、予測対象の因果を説明できなけりゃさ!」(元ネタ「ニュータイプや強化人間だって、艦隊の足を止められなけりゃさ!」)と常日頃思っていたのがまさにそのとおりだと再確認。
また、アテンション構造を意識した、プロンプトを・・・とばかり思っていましたが、アテンション構造はLLMの出力に対して、因果でもなければ相関すらない。あくまでプロンプト内部での相関でしかない。というのを改めて考えさせられる論文でもありました。
LLMが学習した情報は専門分野の人間でも覚えきれないほど豊富で深い内容であることはもはや疑いの余地もなく、それを如何にうまく引っ張って、使える形に組み立ててもらえるか?について、日々、試行錯誤している状況ですが、プロンプトだけでなく、もっと内部構造まで踏み込まないといけないのかと。
2回書け?いや、上手く書け!
巷で噂のGoogle Resaerchの論文を読んでみました。
Prompt Repetition Improves Non-Reasoning LLMs
内容を一言でまとめると、
『同一プロンプトを2回連結して入力するだけで、
ある条件下では、出力長やレイテンシを増やさずに
One Shot Promptの性能が向上する』
という、なかなか夢のある、お話しでした。
どんな条件かというと、論文で提示されていたのは、
①選択肢➡質問という順序のプロンプト
・Prompt Repetitionにより正答率が明確に上昇。
・質問➡選択肢という順序の場合は、性能は落ちはしないが、改善幅は限定的
という非対称な結果に。
②正解が「文脈全体」や「トークンの相対位置」に依存するようなタスク
論部中では、
・長い文章列の中のN番目に登場する言葉・数字を応える
・中央にある要素を特定する
といったもので、Prompt Repetitionが正答率を劇的に向上させる。
となっていました。
このような改善が見られた仕組みは因果アテンションの構造的問題を補っているからということでした。
この構造的問題とは、プロンプトの文章をトークンに分解しトークン間でアテンションをかけるのですが、
自分より過去に出てきたトークンにしかアテンションがかけれない(テキスト生成という能力を得る代償)ため、
文章全体を読み直すことができないというものですが、それを簡単な入力側の工夫で緩和する手法ということで、
「仕組み上、再現性のある」こういったテクニックは実務上、大いに参考になります。
むかし噂になった、スタンフォード大、カリフォルニア大学バークレー校の
Lost in the Middle: How Language Models Use Long Contexts
も長文コンテキストの中央にある関連情報を取りこぼしやすいというのも根幹の原因は同じところにあるのでしょう。
さて、読み終えた後の感想として、真っ先に実務影響を考えるのですが、
正直、「実務でそのまま使えるシチュエーションはかなり限定的」というのが率直な印象でした。
ChatGPTが世に出てきてから何回「アテンション構造、大事。」を説明してきたか分かりませんが、
改めて再認識させてもらえた良い研究でしたし、今後の応用にも期待を寄せています。
んが、コピペを2回してうまくいく分量のものを実務で使うことは少なく(直接自分がChatGPTをたたくときぐらい?)
システム開発用に最新モデルを使っていても、コンテキストウィンドウが強化されているとはいえ、
数万トークンを越えたあたりから、ガクっと落ち込む性能劣化が顕著なので、
アテンションが適切にかかりやすくするために、いまだに王道なのは、
・プロンプトはコンパクトに
・なるべく具体的な記載で
・順序も流れるように
が鉄則で、当社のメンバにも徹底してもらっています。
数万しかないトークン量のなかに、何を含めて、何を除くか?結果何を得たいのか知恵を絞ることが、
エンジニアにとって重要で、決してコピペすれば性能アップでOKという安直な結論に飛びつくわけにはいかないのであります。
HBD
1か月以上遅れたHappy Birth Day。
生成AIのシステム開発適用に関する特許をGPT3.5が出たころに申請していて、そのままにしておいたのですが、会社設立した記念に出願しておいたものが会社の誕生日の前日に無事登録完了することができました。
成果物に対する品質をAIに評価させる手法は色々と提案されていると思いますが、生成AIの本質であるプロンプトによるトークン生成の元となる確率分布の暗黙の操作(アテンション構造を通じた間接的操作)と、それに続く逐次局所最適化の結果として回避不能なハルシネーションを抑制するために、AIの回答を統計的に評価するという、いたってシンプルなアイデアがベースとなっています。もう少し砕けて言うと、良い感じに指示文を選ぶことで期待した結果がかえって来やすいが、それでも結果がぶれてしまうことを、「生成AIの仕組み上、不可避」と諦め・・・受け入れた上で、ブレ方を統計的に評価すれば、実務で使えるか、やっぱダメかの線引きをしやすいですよね?!というアイデアです。確認したい品質の簡単は自由に設定・追加でき(実はここが一番重要だが特許とは全く関係ない)、結果を定量的に扱えるので判断基準が明確になるというメリットもあります。
実は初の特許申請だったので、特許事務所に全部お任せでお願いしていたのですが、特許申請に関する構文が独特過ぎて、ニュアンスというかコンセプトがうまく表現しきれたか自信はありませんが、根底にはそういった想いを込めています。
実はもう一つ、単体テスト工程に特化した方法もあるのですが、特許事務所にアドバイスを頂き、分割出願中です。
AIを使った開発支援に関しては日進月歩どころか時々刻々と新しいサービスが出てきていて、「簡単に〇〇ができる。」、「AIが自動的に〇〇」、「削減効果〇%!」という営業トークが目を引く選択肢が色々と存在します。当社のコンサルティングや製品開発でも試行錯誤をしておりますが、その中でも、「投入効果が高く」、「再現性のある」ものが、「なぜ、ワークするのか?」という【仕組み】をとことん考えて選んでいきたいですね。
なお、余談ではありますが、当社の会社設立日は代表の誕生日でもあったりします。2ヵ月でも、3ヵ月遅れでも、お祝い大歓迎です♪
CDM
FINOSという金融業界のオープンソース化を推進しようという団体がCommon Design Model(CDM)というデータモデルを提唱している。GS, JPM, MS, UBS, Barclay等々の業界のTopTierの銀行やISDA, ISLAといった業界団体が共同で進める金融データ(デリバやレポ)の標準データモデルである。えー、それってFpMLじゃないのー?と思ったあなた!私も初めて目にしたとき、同じ印象を持ちました。。。お客様や周辺の金融業界人も、ほぼ同じ反応をします。ただ、今度のモデルは一味違います。一言で説明するのが難しいのですが、Building Blockによるデリバティブ取引の経済条件&イベント処理の表現の標準化と構造化と理解しています。とくにこのイベント定義と処理フローをモデル化しているところが肝です。取引条件を柔軟に表現することができるのが静的な表現力だとすると、取引のライフサイクル管理のモデル化は動的な表現力と言えるかもしれません。
Building Blockといえば、10年前にエキゾチック・デリバティブの評価ロジックの延長としてCVA評価モデルの開発などを行っていましたが、洗練されているとは言い難いものの、Building Block的にInstrument定義をして、それに対応した評価ロジックを当てはめて、少なくとも定義されたBlockの組み合わせの範囲では、汎用的に評価できるものを実装していました。そのさらに10年ほど前には色々な仕組み商品が登場しており、当時の私は計算ライブラリのプロトタイプも実装していたのですが、原型をとどめないまでに、ことごとく書き換えてくれた、C++の先輩から、「仕組系のデリバティブ商品のプライシングこそ、オブジェクト指向的に実装すべきだ。」と言われ、「あ、確かに~?!」と、目が覚めるような気付きがあったことは今では懐かしい思い出です。(いや、新人の頃から目にしてたクォンツライブラリのコードが、引数つぎはぎだらけだったのですがそれが当たり前だと疑いもしていませんでした)
当時のお客様から、ビジネスのスピード感を失わないような商品拡張ができる基盤が必要だと何度も言われ続け(・・・今も?)、ビジネスドメイン知識を体系的に構造化し、それをオブジェクト指向で表現するのが最も適していてその解としてBuilding Blockを提唱していたのですが、中々、エンジニア陣の理解を得ることが難しかったので、自チームのライブラリをBuilding Block型にリファクタしてました(=先輩が)。
ただ、評価ロジックの内部はイベント管理を行う必要がなく、イベント適用後の状態でデータを受け取り、ペイオフ評価をするだけ(*)だったので、商品性表現にしか力を注いでいなかったのですが、今回、CDMについてキャッチアップするにつれ、イベント処理周りも標準化しているところが、久しぶりに「あ~、確かに~?!」となりました。
現在、お仕事絡みで、色々調べて、動画見て、深夜時間帯のワークショップやWGに参加して、アイデアまとめて、試作品を作ってます(=生成AIが)。
業界全体のコミュニケーション・コスト抑制が、本取り組みの背景にあるとは思うのですが、金融機関内部の非競争領域のコスト削減というテーマでみても重要な、もっと日本で広まるべき技術だと思っているので、CDMネタはもう少し続きます。
*: CVAの場合は将来複数時点のシミュレーションをしているので、経路依存性を適切に評価する必要があり、その範囲でイベント考慮が必要でしたが、ここまで整備はしていませんでした。
巧遅拙速?

ここ最近、AIによるシステム開発周りのニュースや問い合わせが多くなってきたため、調度1年前に発表され、当時、読み解いた論文を引っ張り出してみることにしました。2025/8/20に更新されたようなのでざっと斜め読みもしてみました。
“The Effects of Generative AI on High-Skilled Work: Evidence from Three Field Experiments with Software Developers”
MIT、Princeton、Pennsylvania、Microsoftが発表したコード支援AIのシステム開発における生産性について分析した論文で、マイクロソフト、アクセンチュア、匿名の大手企業で、通常業務の一環としてGithubCopilotを導入した場合・しない場合の5000人規模のランダム化比較試験を行ったという分析。
業界の注目度も高く、DL数3万越えで注目度は高い(ただ、まだ査読前のためか引用数は少ない)。
ここ一年、日本語で解説しているページも増え、自身の理解との対比にも役立っている。
筆者らの主張は、補強材料を増やしただけで前回と大きく変わらず、主な結論は
・利用した開発者の完了タスク数が26.08%(標準誤差:10.3%)増加したことが明らかになった。
・特に、経験の浅い開発者ほど導入率が高く、生産性の向上も大きかった。
というもので今後の発展に期待が寄せられる内容となっている。
しかしながら、ちょっとこの論文は気を付けなくてはならないところが散見される。
完了タスク数はPullRequestsのことで、Build Success Rateは-5.5% (p検定は通らず)。
アクセンチュアのサンプルに限ると、Buildは脅威の92%Up(有意)である一方、成功率は-17.4%(有意)。
と読める部分は華麗にスルーされており、
「あれ?作業早くなったけど質が落ちているよね?」
「あれ?ベテラン開発者の生産性、マイナスになっている部分多くない?」
「え?なに?結局、ベテラン開発者に今以上のしわ寄せが???」
など、口の悪い読者(誰?私?)には「Microsoftの提○論文じゃないかー」と言われていたとか、いないとか。
筆者らに同様の反響があったからか、今回の改訂された論文ではコード品質について追加の分析を行っていました。
Microsoftのサンプルでの分析結果の要約は
・コード品質を正確に測定するのは難しい
・PRの承認率は10%上昇(有意)
・Microsoft内では、コード品質の低下を示す証拠は見当たらない
・一方、アクセンチュアでは成功率低下してるけど影響は個社毎に違う可能性ある
というもので、歯切れが悪く、う~ん、ちょっとなぁ~。という印象。
PR完了までの時間は7時間悪化している点はやはりスルー。(有意ではない結果なので嘘ではない。ただ、ポジティブ・バイアスが随所にあると感じてしまう。仕方ないのだが・・・。)
でも、普通に単体テストの指標とか出せばよいのにとは思います。
まぁ、ジュニア開発者が担当部分をずっと抱えっぱなしで期限切れか直前になって「やっぱり無理でした!」と言われるぐらいなら、たたき台をサクッと作ってもらった方が、時間の有効活用にはなるので、導入は積極的にすべきだとは思っています。
入れる際に、品質改善もセットでどう使うのかが重要ですね。と、1年前と同じアタリマエの結論になりました。
ジョブ・チェンジ

金融機関のクォンツがAI企業にラブコールを受けているというニュースが目に入った。
AI企業(LLM開発)が新人レベルのクォンツに対して30万ドル(ボーナス抜き)で提示されているとか。(生活費も高いから日本だったら2,000~2,500万円ぐらいの感覚か?)
記事によれば、ユーザーへの応答速度を競っているAI企業が、アルゴリズムの遅延を最小限に抑える技術などを有するクォンツを高く評価しているという。非構造化データの解析を伴うということなので、クォンツ運用でアルゴトレードの方かな?
ロケット・サイエンティストがウォールストリートに流れ、さらに21世紀でもっともセクシーな職業(死語?)へという大きな流れの中で、専門スキル人材の極端な需給ギャップによるものと思われるが、しばらくは続くのだろう。
広い意味でセルサイド側のクォンツ(筆者はセルサイド側の経験が大半で、バイサイド側のHFTは未経験)も含めて言うと、GPT-4の段階で既に新人クォンツ以上の性能と思っている。
「Pythonで3万件のオプションのフルリスク計算して」をミリ秒未満で処理するコードを数値チェックや効率化などの指示のやり取りで30分で完成させたり、アメリカン・モンテカルロ法の試作品をものの数分で実装してきたり(GPT3.5では不可なタスクだったのに)。
コーディングだけじゃなく、トレーディング業務やリスク管理業務も(一般人と比べると)精通していて、その上、会計や税制や法務や翻訳や、いやもうなんでも、新人以上に頼りになる存在となっている。なのに支払うべき報酬はたったの数万円。金融工学が仮定するノー・フリー・ランチの大原則に従えばこの裁定機会は近い将来、解消されてしまうはずだ。
理系頭脳が殺到する次にくる職業はなんだろうか?(筆者はザ・文系)
出典:Bloomberg News「年収4000万円、AI業界が狙うクオンツ人材-ウォール街から流出加速/原題: Open AI, Perplexity Make Pitch to Recruit Quant Traders From Banks」(2025年8月11日)
https://www.bloomberg.co.jp/news/articles/2025-08-11/T0OATAGOYMTF00
AI三銃士 その②

今日のネタは今やAIの代名詞となった
生成AI:Generative AI(特にLLM)

LLMのお仕事は、x1~xi-1をプロンプト(+それまでに生成された文章)をインプットとした「次の単語の予測」
AIの仕組み:
インプットした文字列に対して、AIが覚えた言葉を意味は考えずに出現確率が最大となる文字列を返してくれる。
インプットの内容に応じて裏側で作っている確率分布が変わるので、
①ふわっと聞くと、ふわっと返してくれる(確率分布の裾が広がってしまっているので毎回答えが変わったりする)
②細かく詳細に絞って聞くと、かなり的確に返してくれる(確率分布の分散が小さくなり答えが安定する)
アテンション構造という文章内の言葉(トークン)同士の関係性の強弱を判定してくれる仕掛けのおかげで、長い文章を与えてもそれなりにこちらの意図を把握してくれているかのような出力をしてくれる。
構造的、かつ、順序だてて指示を出すとかなり高い精度で質の高いアウトプットを出力してくれるのはこの仕組みのおかげで、「あなたは○○のプロフェッショナルです。」という謎のプロンプト文の枕詞のおかげではないと信じている。(確率分布の大枠は狭まるだろうが)
プロンプト・エンジニアリングは「○○すると良いというTips」を覚えることではなく、モデルが暗記した内容を仕組みを理解した上でどうやったら上手く引き出せるかを考え抜くことがとっても重要。
得意分野:
・文章生成、文章校正、他言語翻訳、長文要約といった自然言語の処理は全般的に得意
・プログラムの実装やソースコードからの仕様書逆引きなどプログラミング言語と自然言語の翻訳も得意
不得意分野:
・集計、計算、予測、論理思考等々
ハルシネーションに対する考察:
AIが息を吸うように嘘をつく回答をしてくるので信頼できないと心無い一部の人間から批判を受けるが、それは、学習とかファインチューニングと呼ばれるスパルタ教育を通じて暗記した言葉の中から、あなたの問いかけに対して、暗記した内容を尤もらしく応答するように振舞うように躾けられているので、一定、理解してあげないといけない。人として。
RAGという、これまで暗記していなかったニッチな知識も付け足してあげれば解決するというアイデアもあるが、持ち込み可の試験のようなもので、結局、参考書の使い方を教えてあげる家庭教師をつけなくてはならず、分厚い参考書だけ持ち込んだだけでは正解を探す労力が増す一方で、どんどん正答率が落ちるという悲しい結末を迎えることも多い。優秀な家庭教師(=残念ながら当社ではない)を雇うことで改善するのだろうが、そこまでお金かけてやること?という素朴な疑問が常について回る。そもそも、検索してLLMに渡す情報が正確ならば、既に「正解」にたどり着いてるじゃないか・・・。
検索に揺らぎがあるならLLMがどんなに優秀なモデルでも、別の「嘘」が作られてしまうじゃないか~・・・。
当社がやる場合は、ベクトル検索へ期待を捨て、RAGに入れるデータの目次を作成する(構造化されたタグ付け)
人間が分厚い本から知りたいこと調べる時、目次確認して、巻末の用語から記載ページ(所謂インデックス)を確認するのと同じ発想。
コンテキストウィンドウに載る量まで絞り込めれば、LLMの文章読解&要約力はベクトル検索なんかよりもよっぽど信頼できるので任せる。
・・・って世の中では普通にやってるところありますね。
あとは、利用後の問い合わせのモニタリングが大事で、多く寄せられる質問=重要、少ない質問=精度低でもやむなしと割り切り、皆が使い続けることにより賢くなり、8割の人が満足してくれるものを目指すのが現実解ではないかと思うのですが如何でしょうか?
正直、システム開発でLLMを使う上では、従来通りのテストやレビューで打ち取れる問題なのでハルシネーションなんて気にしてないです・・・というのはここだけのお話し。
AI三銃士 その①
仕事で目にする、予測AI、生成AI、因果AIについて日々の雑感です。今日は予測AIについて。
予測AI:Predictive AI
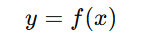
AIの仕組み:観測された過去データへのフィッティング(機械学習という呼称の最適化)
成功の条件:予測対象yに対してxが因果関係を持ち、かつ、その関係性が一定期間持続(社会科学、特に金融市場では稀)
失敗の事例:数多くあり過ぎて書ききれない
相関=因果という信仰(著名な金融研究者によれば、ここ数十年の資産運用系の金融論文のほとんどがコレ)
y(t+dt), x(t)でdtが限りなくゼロかマイナスになっている(dt=0: 実行不可能解、dt<0: 未来情報漏洩=ズル)
xが操作・介入できない(so what問題)
さらに進化して、y = y(I know!! 問題)
<ユースケース検討時の分類>
① yがビジネス上のベネフィットと直接リンクしており、xが自ら介入・操作できる変数となっている問題になっていれば、単純な最適化問題であり、それこそ機械学習(=最適化アルゴリズム)が最も真価が発揮される領域。残念ながらそんなに都合よく見つからない。
② xが操作できなくても、予測後にyの実現値が観測される前に、yの予測結果に基づき行動可能でベネフィットが得られる問題で、需要予想にもとづく仕入れ最適化や株価予想にもとづく投資戦略決定など、ユースケースが最も多い領域。反面、失敗事例も多数。
③y, xが同タイミングでもxを予測することで②の問題として定義できる領域。(天気予報など一定の予測精度が担保されている場合には有効)
④ y(の変化)のxによる要因分解。気づきが得られる可能性が少しだけある(ただし、因果は考慮されない)
ハイレベルにはこういった基礎の基礎を念頭におきながら、是々非々で検討を行っています。
こういったアタリマエのことが置き去りにしたまま進めていって成功した事例をまだ見たことがないです。
データ・エンジニア(≠データ・サイエンティスト)としてAIのコンサルティングのお仕事をさせて頂いておきながらなんですが、
「予測AIを使わないと解決できない問題はない」という信条のもと、何故AIでやるのか、期待値をどう設定するのが妥当なのか、という点をいつも議論させて頂いています。